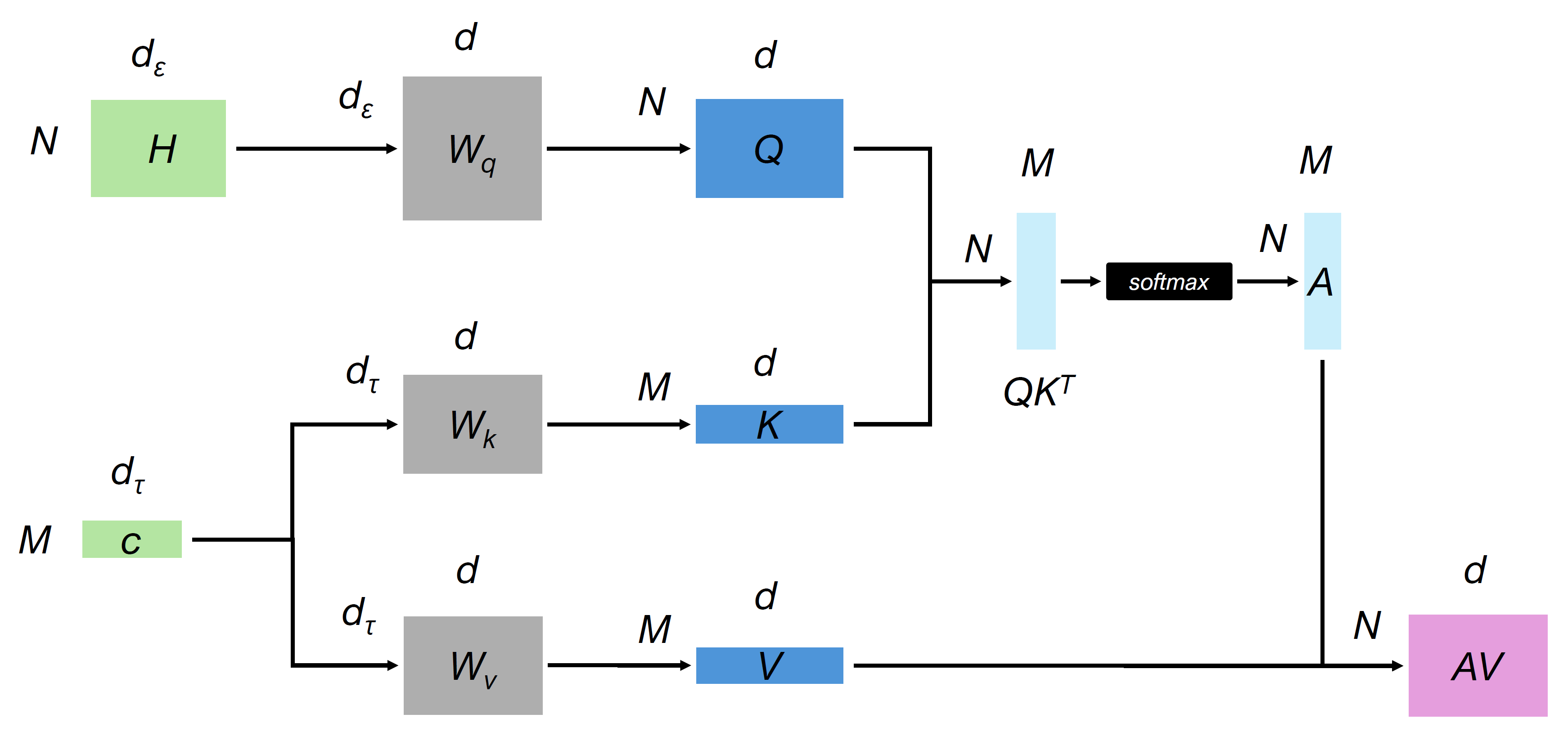
We show a visual representation of the attention layer in the UNet and the sizes of the different tensors involved, where:
|
$W_q, W_k, W_v$ : attention weight matrices $Q, K, V$ : query vectors, key vector, value vector $A$ : attention matrix $M = 1$ the channel dimension of the condition vector. $N = \text{nb pixels} = h \times w$ the flattened size of the UNet features. |
$d = \text{layer channels} = 320 \times \text{channel_mult}$ $d_{\varepsilon} = d$ $d_{\tau} = 1024$ dimension of the condition CLIP embedding. $H$ : tensor of flattened pixels (spatial resolution $h \times w$) $c$ : conditioning embedding |